
LLM Powered Lyric Generation
Can robots write in Iambic Pentameter?


Recently, I became intrigued by the application of large language models (LLMs) to lyric generation and correction, as well as the linguistic and engineering challenges this entails.
LLMs are powerful writing tools capable of emulating talented poets, but the nature of tokenization makes it difficult for them to generate text with a specific number of syllables or vowels. Moreover, they lack a humanlike understanding of meter, even though they perform reasonably well. To effectively use LLMs for lyric generation, constraints and verification mechanisms are necessary. This necessity inspired the creation of earl-llm, a NodeJS-based lyric generation pipeline that utilizes GPT-4o for generation (but you could drop any model into it and it would work fine). In this blog, I will discuss some of the engineering problems I encountered and share further thoughts on LLMs and creativity.
Considerations and Constraints
Tokenization
Tokenization is the root of all our engineering challenges to be solved. For those unfamiliar, tokenization is a method of representing strings of letters numerically by breaking them down into sub-word units. For example, the word “camembert” might be divided into “cam_emb_ert” and then these represented units are converted into a numerical mapping, leaving you with an array of numbers like this: [11860, 9034, 531]. Mistral provides an excellent detailed breakdown of their tokenization method here. This technique is crucial for allowing large language models (LLMs) to analyze and generate text. However, it poses challenges for a few specific tasks we’ve concerned ourselves with.
Syllable Counting
While LLMs seem like they should be quite proficient at managing tasks like producing lines with a specific number of syllables, they can never be perfect due to the inherent limitations of tokenization. This discrepancy arises because tokens don’t always align perfectly with natural linguistic units like syllables, making it challenging for LLMs to consistently meet precise syllable requirements. For instance, OpenAI’s Tokenizer splits the word “tokenization” into “token” and “ization”, whereas splitting the word by syllables would leave us with something like “to_ken_i_za_tion”. If LLMs are to be used in lyric generation, properly counting syllables is certainly a problem that is necessary to solve, and it cannot be deterministically solved with LLMs themselves at this time. One recent study found that even the largest and best performing models are only successful at hitting the proper number of syllables about 55% of the time at best.
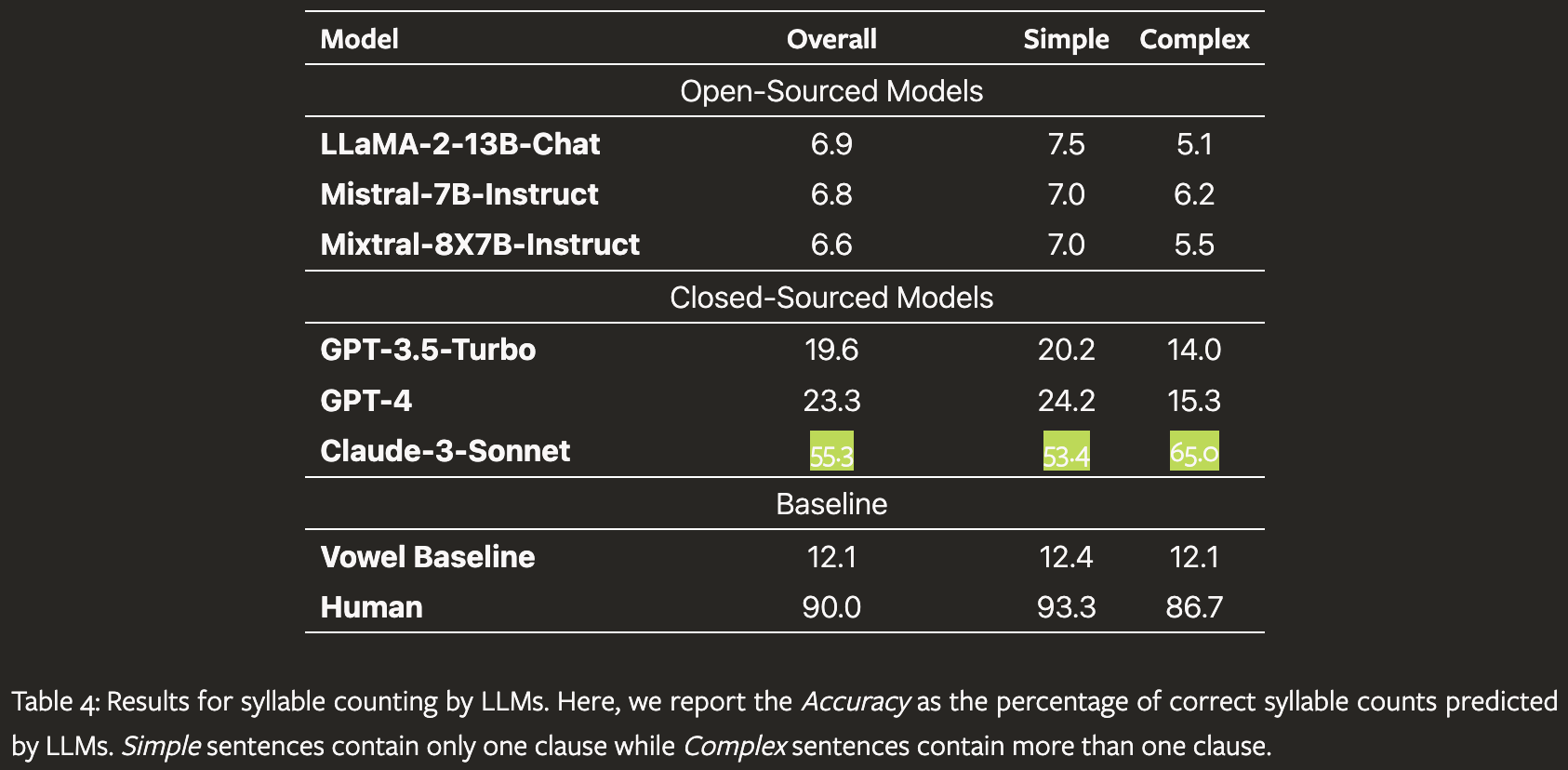
Rhyming
Rhyming comes more naturally to large language models (LLMs), yet they still lag behind human proficiency. According to the same study mentioned earlier, the most advanced models achieve a rhyming success rate of nearly 70%, which is pretty decent but not sufficient for large-scale use in lyric generation. Interestingly the gap in performance slightly narrows when comparing the “Rare Words” scores. Another fun engineering problem to solve!
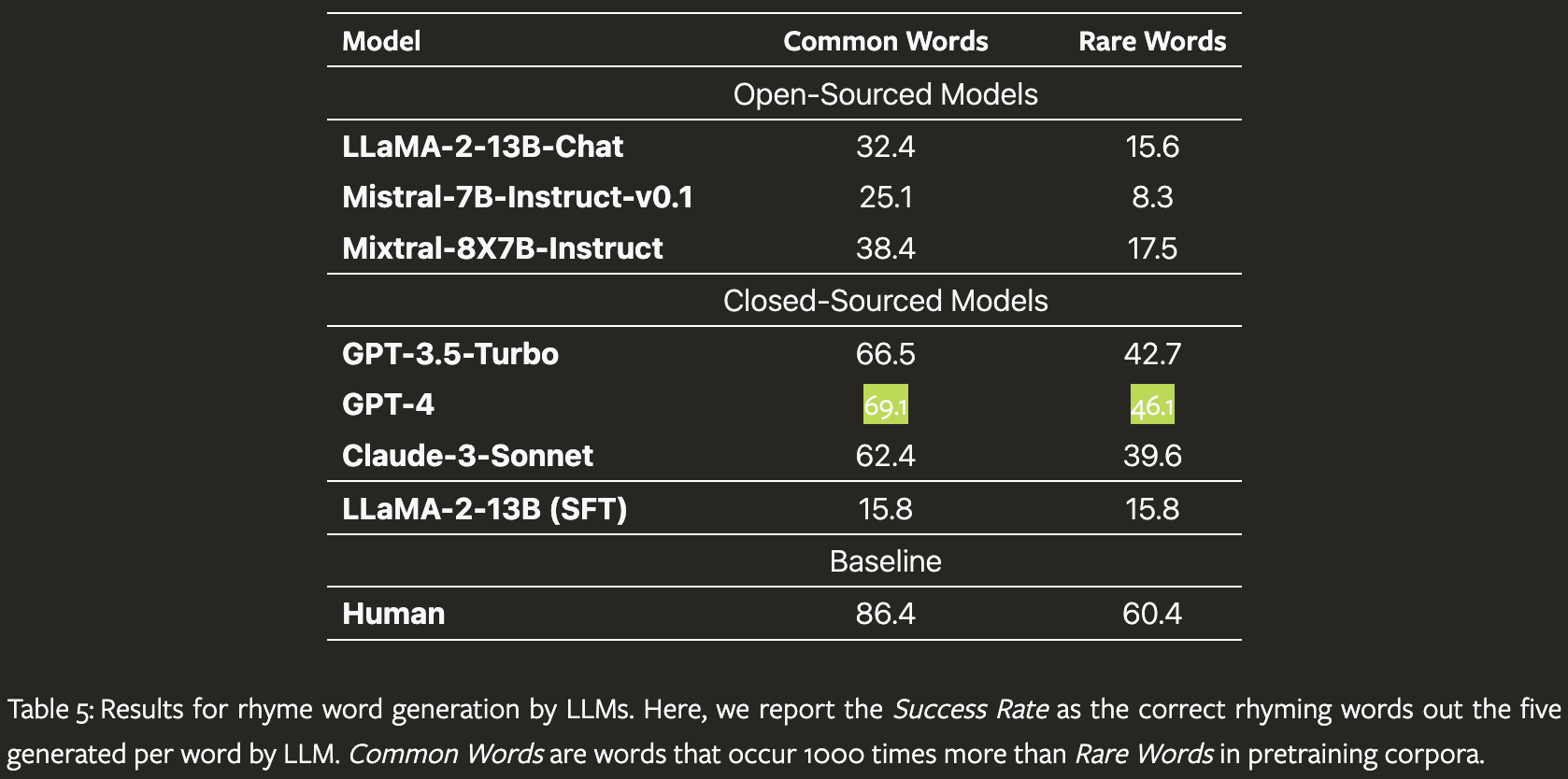
Metric Parsing
Metric parsing presents a significant challenge, not only for large language models (LLMs) but also for humans. The intonations and stresses we use can change a verse from one meter to another, and this nuanced information is effectively inaccessible to LLMs during the inference process. While computational metric parsing can offer some assistance, it remains limited. However, since we aim to have computers write lyrics, relying on this technology is essential to achieving our goals. Thankfully humans are an industrious species, and we’ve already developed some vital tools, making this a useful segue to my next section.
Engineering
It’s not very complicated in the end, but as a visual aid and mental model here is a Conceptual Overview of the loop I built. We will talk about each part in full.
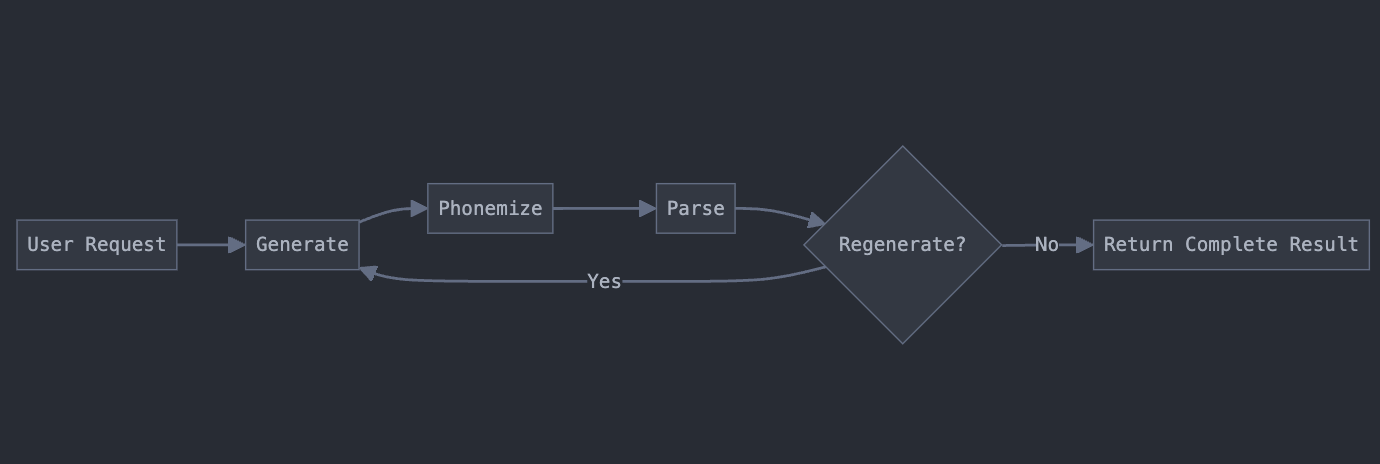
User Request and Generate
I chose to represent songs as a series of components, with each component taking on a shape like this:

The lineLimit is pretty self-explanatory, but the meter is perhaps unintuitive at first glance. I chose to model meter as an array of arrays, each internal array representing one line respectively. The internal arrays only ever contain ones and zeroes, a 0 represents an unstressed syllable, the 1 represents a stressed syllable. The meter is applied in an alternating pattern, so the result of the request above would be a verse 8 lines long, with 4 lines being 8 syllables long, and the interleaved 4 would be 4 syllables each. This data is all fed to the model as part of a user prompt as seen in the example below. The song components are generated sequentially and the current state of the generate song is passed to each generation request to ensure narrative and thematic coherency.
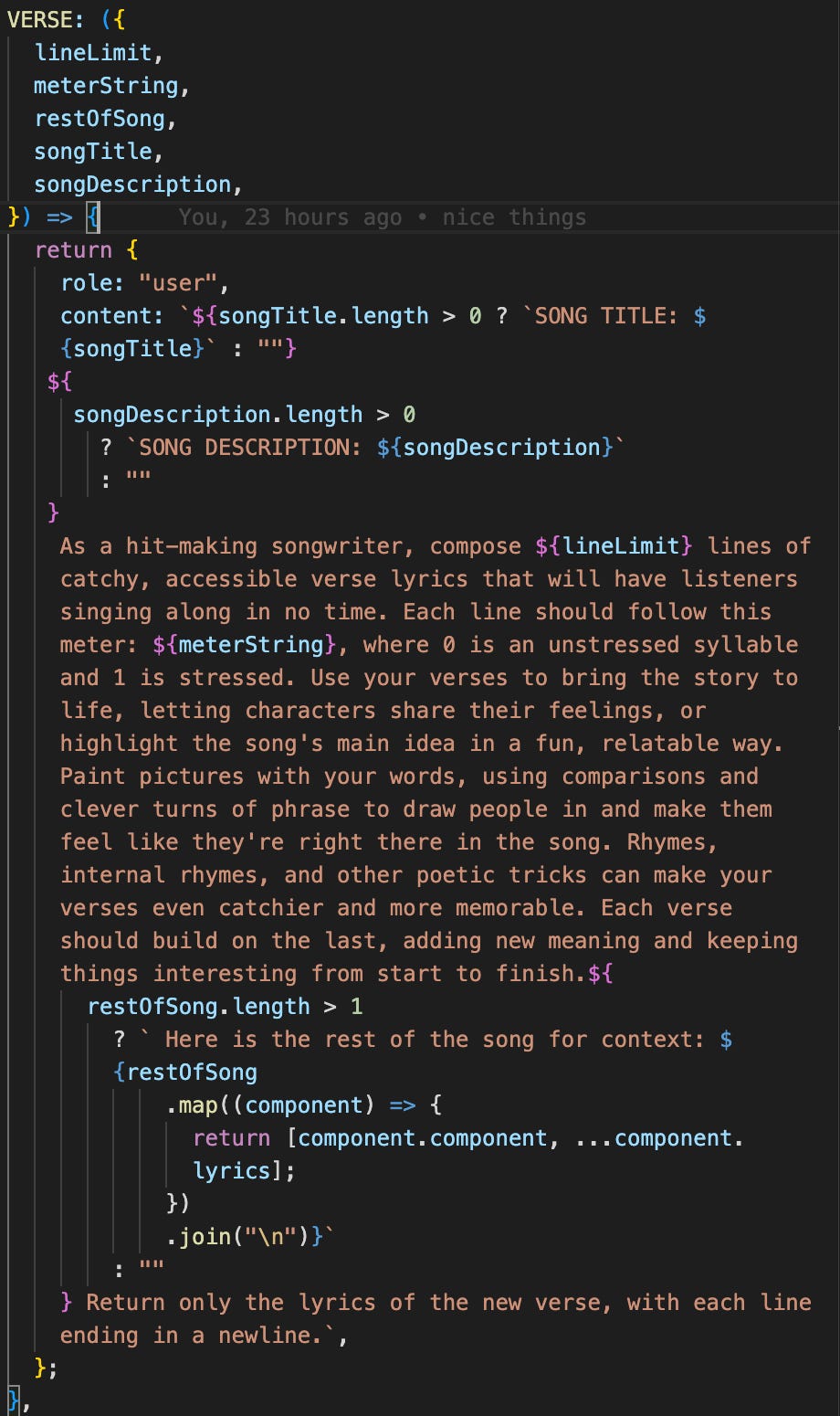
The prompt itself was a collaborative effort between GPT-4o, Claude Sonnet 3.5 and myself. I wrote the original prompt, and then I had GPT-4o and Claude help me refine various aspects of it. 4o was excellent in providing tips on controllability, while Claude helped enhance the creativity.
Phonemize
Phonemize is both the title of this subsection, and the name of a library that was essential to my work. Part of the problem with this project is that the Latin alphabet, particularly the variant favored in the English speaking world does not encode data about the stress of a syllable, therefore it is necessary to transform our text before we begin the work of parsing.
The option I chose to do this is the International Phonetic Alphabet (IPA). The IPA is a set of symbols that represent particular phonemes, each of which corresponds with the particular sound of a syllable or consonant. The word “hegemony”, for example, would be transcribed as `hɪˈɡeməni`. The apostrophe character in the string indicates where the primary stress falls, and the remaining syllable characters are unstressed. Some words will also have a secondary stress, which is represented by the `ˌ` character. This allows for easy parsing in the next step. Currently we are only concerning ourselves with meter enforcement, but phonemization will also make some other phonetic and metrical enforcements (such as rhyme) possible down the line.
Phonemization itself is very straightforward, I simply split the string returned by the LLM in the previous step, phonemize each word, by matching it against json library provided by the Phonemize package, and then store it in an array for further parsing. We also cache the results for efficiency.

In the case a word is not found in the phonemization library, espeak is used as a fallback. Espeak is a computer accessibility utility allowing for text-to-speech capabilities on Linux and MacOS based systems, and it has an option to, instead of playing audio, return the predicted phonemes of the string it is passed. Espeak itself does not have a direct JavaScript implementation with the features I needed, so it was necessary to spawn as a child process.
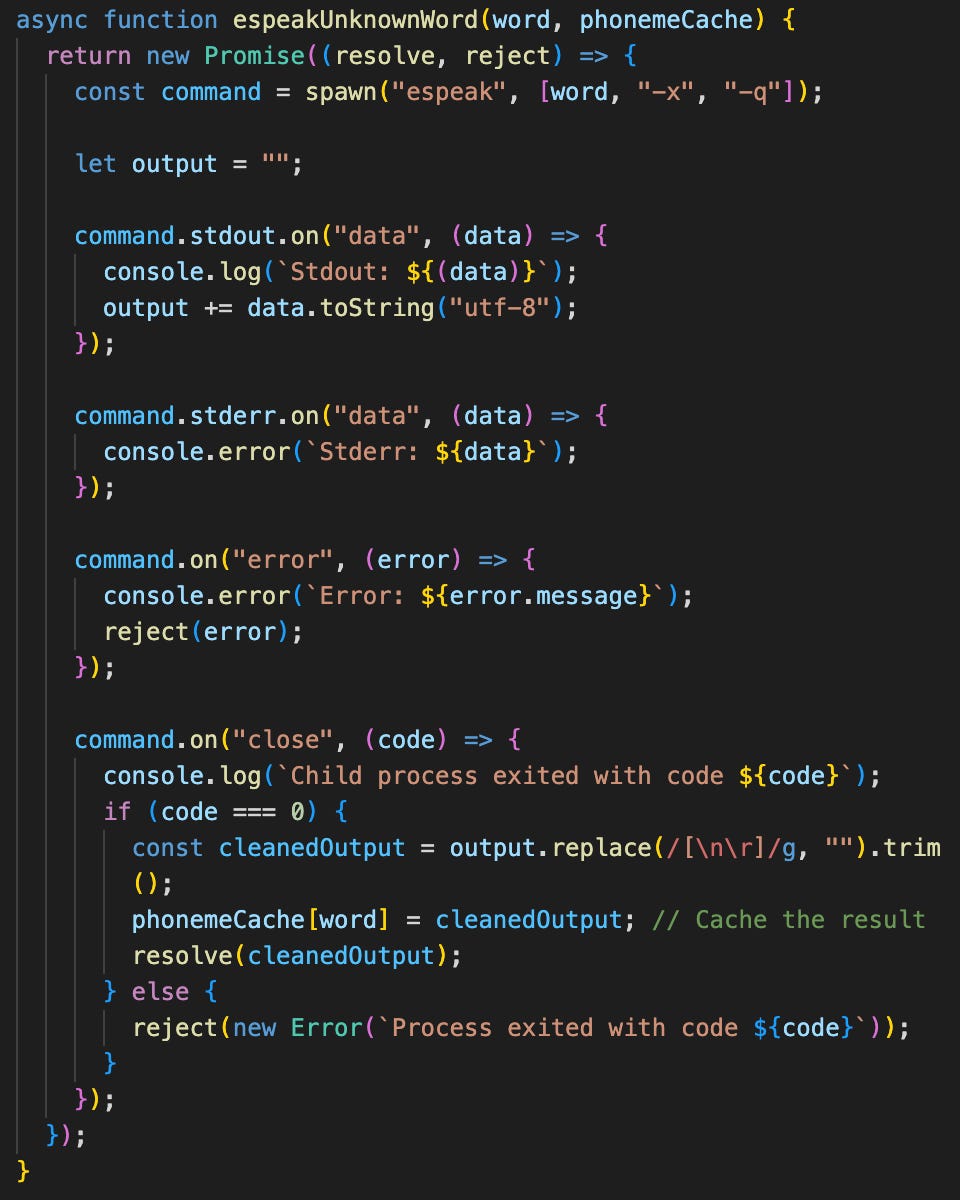
As we did above, we cache the results so if we run across the same word again we can simply access it instead of recalculating.
Parse
Next, we parse. We run each word through a regex parser, and store the results in an array that looks like this:
[
{ originalString: "example", phoneme: "ɪɡˈzæmpəl", syllableCount: 3, syllableStress: [1, 0, 0] },
{ originalString: "text", phoneme: "tɛkst", syllableCount: 1, syllableStress: [1] },
{ originalString: "for", phoneme: "fɔːr", syllableCount: 1, syllableStress: [1] },
{ originalString: "parsing", phoneme: "ˈpɑːrsɪŋ", syllableCount: 2, syllableStress: [1, 0] }
]The syllable stress array of each word is mapped by isolating the syllables from each phonemized word, and then detecting the stress of the syllable based on the presence of the aforementioned stress indicators.
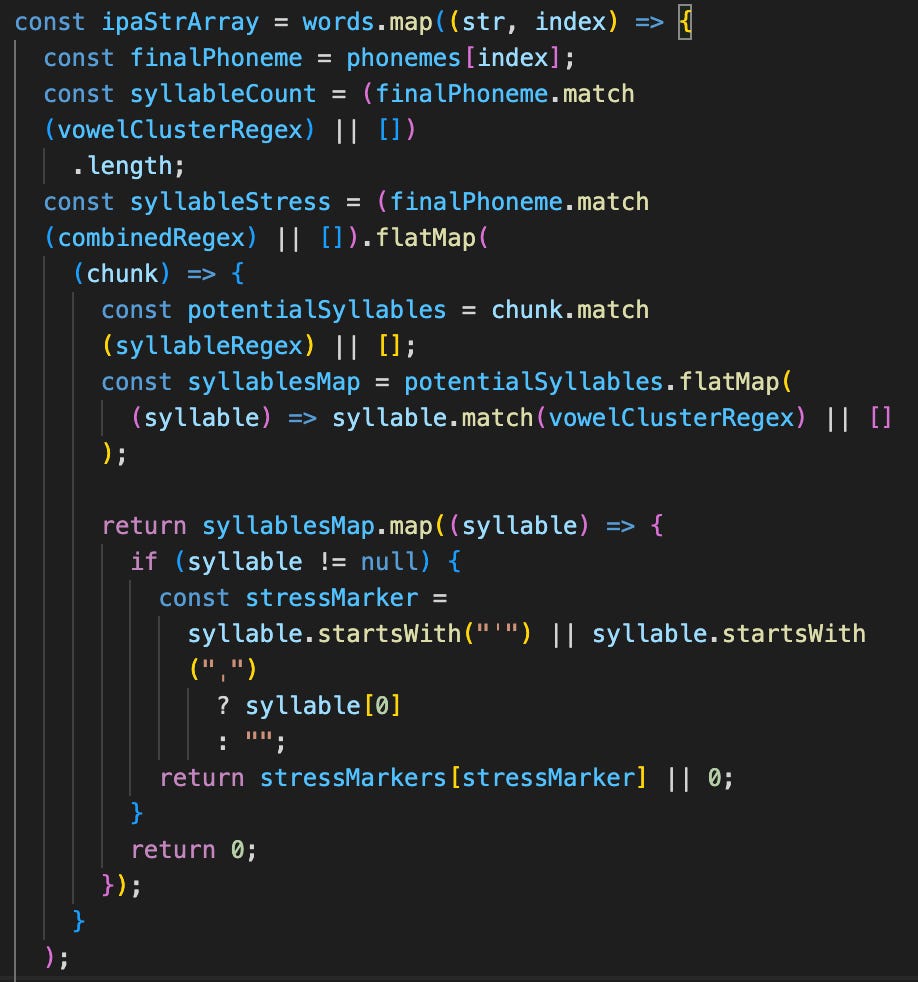
This result is then checked line by line for metric accuracy using a slight modification to a Hamming Distance algorithm. A Hamming Distance measures the difference between two arrays of equal length, however in our case we cannot always guarantee the meter arrays specified and the meter arrays generated will be of identical length, and we also don’t need to ensure that we they are always identical, just that they’re close enough. In songwriting, varying the number of syllables per line and not getting too repetitive can vastly improve a song, so a modified approach to Hamming Distance like the one below is perfect for this project.
function hammingDistance(intendedMeter, currentMeter) {
let distance = 0;
for (let i = 0; i < currentMeter.length; i++) {
if (intendedMeter[i] !== currentMeter[i]) {
distance++;
}
}
return distance;
}Once the distance for a line is calculated, if the distance exceeds 2 it is sent to be regenerated. 2 was largely an arbitrary choice based on the fact that under 2 would lead to excessively long generation timeframes, and over 2 felt like too much deviation from the specified song grammar.
Regenerate
The regeneration obeys the same system prompt as the original request, but the user prompt is customized to ensure correction.
const chatCompletion = await openai.chat.completions.create({
temperature: 1.2,
messages: [
{
role: "system",
content: SYSTEM_PROMPTS[selectedSystemPrompt],
},
{
role: "user",
content: `As a skilled lyricist, please revise the following lyric to contain exactly ${targetSyllables} syllables, as it currently has ${currentSyllables} syllables. When rewriting, ensure that the revised lyric follows this specific meter pattern: ${meter.join()}, where 0 represents an unstressed syllable and 1 represents a stressed syllable. Maintain the original rhyme scheme and preserve the overall meaning and intent of the lyric provided. Focus on making the necessary adjustments to the number of syllables while maintaining the artistic integrity of the piece.
Lyric to revise: ${lyric}
${
currentLyrics.length > 1
? `Here is the rest of the song for context: ${currentLyrics
.map((component) => {
return [component.component, ...component.lyrics];
})
.join("\n")}`
: ""
} Return only the revised lyric, ending with a newline character.`,
},
],
model: "gpt-4o",
});This loop is repeated until the generated line is within the error margin specified in the code, and then it is returned to user.
Frontend
Last bit of engineering work was done in the frontend! Once a song is generated, a user is able to interact with the generated song to regenerate single words using a technique called fill-masking or add new lines using a GPT-2 integration, both run locally on the client by making use of a library called Transformers.js. I briefly considered using another option called ONNX, but it had more overhead to using it than I felt like dealing with, and Transformers.js uses ONNX under the hood anyway. (If you’re interested in seeing an ONNX/Next.js implementation of bert-base-uncased fill masking you can check out a demo repo I wrote here.)
Check back in a couple weeks for more engineering details around the hosting of the project.
Conclusion
The intersection of music and artificial intelligence presents an exciting frontier for creative exploration, and this is just the beginning of work on this project. There are new paintbrushes and typewriters to be crafted.
The engineering challenges we've explored – from tokenization issues to syllable counting, rhyming, and metric parsing – underscore the intricate nature of language and poetry. While LLMs have made remarkable strides in generating human-like text, their struggles with the nuanced aspects of lyric writing reveal the depth of human linguistic and musical intuition.
Our journey through the development of earl-llm, a NodeJS-based lyric generation pipeline, demonstrates how we can leverage the strengths of LLMs while implementing necessary constraints and verification mechanisms. By combining the generative power of models like GPT-4 with carefully designed phonemization, parsing, and regeneration processes, we've created a tool that bridges the gap between AI capabilities and the structural demands of songwriting.
It's crucial to emphasize that the intent behind this project is not to replace human artists but to augment and expand their creative toolkit. AI-assisted lyric generation can serve as a wellspring of inspiration, a collaborative partner, or a means to overcome writer's block. It opens up new possibilities for experimentation and pushes the boundaries of what's possible in songwriting.
As we continue to refine and improve these technologies, we're likely to see even more sophisticated integration of AI in the creative process. The future of music may well involve a harmonious collaboration between human creativity and artificial intelligence, each complementing the other's strengths.
In conclusion, while AI may never fully replicate the depth of human emotion and experience in songwriting, it offers an invaluable set of tools that can enhance and inspire the creative process. As we stand at the cusp of this technological revolution in music, it's an exciting time for artists, technologists, and music lovers alike to explore the potential of AI-assisted creativity.
I invite you to try out the demo of earl-llm and experience firsthand the possibilities that arise when we combine the power of AI with the art of songwriting. Who knows? Your next hit song might be just a few algorithms away.
Check it out here: https://earl-fe.vercel.app/
The backend code can be found here: https://github.com/slee1996/earl-llm